भारतीय अर्थव्यवस्था
अध्याय: 4
- 21 Oct 2019
- 18 min read
डेटा ‘‘लोगों का, लोगों द्वारा, लोगों के लिये’
संक्षिप्त विवरण
यह अध्याय वर्तमान डिजिटल अर्थव्यवस्था में डेटा के महत्त्व को रेखांकित करता है तथा यह भी बताता है कि जन कल्याण हेतु डेटा का लोकतांत्रिकरण किस प्रकार भारत को परिवर्तित कर सकता है। यह डेटा से संबंधित मुद्दों को संबोधित करता है तथा डेटा के लिये उचित परिवेश के निर्माण हेतु मार्ग भी सुझाता है।
आँकड़ों (डेटा) और सामाजिक कल्याण का अर्थशास्त्र
The Economics of Data and Social Welfare
- हाल ही के वर्षों में विश्व सूचनाओं के विस्फोट यानी प्रकाशित आँकड़ों के परिणाम में चरघातांकी वृद्धि का साक्षी रहा है।
- चूँकि लोग एक दूसरे से बात करने, सूचनाएँ प्राप्त करने, वस्तुओं एवं सेवाओं का क्रय करने, बिलों का भुगतान करने, वित्तीय बाज़ारों में लेन-देन करने, टैक्स फाइल करने, कल्याणकारी सेवाओं का लाभ लेने तथा स्थानीय नेताओं से संपर्क रखने के लिये डिजिटल सेवाओं का भरपूर उपयोग कर रहे हैं अतः एक अभूतपूर्व पैमाने बफर आँकड़ों (डेटा) का सृजन किया जा रहा है।
- डेटा में बाज़ारों को राष्ट्रीय स्तर पर एकीकृत करने, बिचौलियों की आवश्यकता को कम करने, अंतिम उपभोक्ताओं के लिये कीमतों को घटाने और किसानों के लिये कीमतों को बढ़ाने की सामर्थ्य होती है।
- कुछ दशक पूर्व तक, जिन आँकड़ों को प्राप्त करने में एक श्रमसाध्य सर्वेक्षण करना पड़ता था वे आज शून्य लागत पर संचित हो रहे हैं, यद्यपि वे विविध स्रोतों में प्रकीर्ण रूप में हैं।
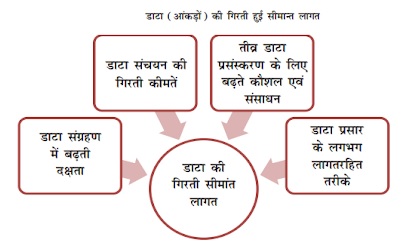

डेटा क्या है ?
- यह सूचनाओं का डिजिटल रूप है जो प्रायः संसाधित होता रहता है।
डेटा किस प्रकार सृजित होता है?
- लोग जब डिजिटल सेवाओं का उपयोग जैसे- बातचीत, सूचना प्राप्ति, सेवाओं और वस्तुओं का क्रय-विक्रय, बिलों का भुगतान, वित्तीय बाज़ारों में अंतरण, कर अदायगी, कल्याणकारी योजनाओं का लाभ लेने आदि के लिये करते हैं तो बड़े पैमाने पर डेटा का सृजन होता है।
डेटा का प्रकार
- अनाम डेटा (Anonymized Data): इस प्रकार का डेटा किसी व्यक्ति विशेष से संबंधित नहीं होता फिर भी इसमें व्यक्तिगत स्तर की सूक्ष्म जानकारियाँ मौजूद होती हैं।
- सार्वजनिक डेटा (Public Data): इस प्रकार का डेटा न ही किसी व्यक्ति विशेष से संबंधित होता है और न ही इसमें व्यक्तियों से जुड़ी सूक्ष्म जानकारियाँ होती हैं।
सरकार के लिये डेटा की उपयोगिता
- नागरिकों की जीवन की गुणवत्ता में वृद्धि करना,
- नीति-निर्माण को अधिक प्रमाणिक बनाना,
- कल्याणकारी योजनाओं के लक्ष्यीकरण में वृद्धि करना,
- विखंडित बाज़ार को एकीकृत करना,
- ऐसी आवश्यकताओं की पूर्ति करना जिन्हें अभी तक लक्षित नहीं किया गया,
- सार्वजनिक सेवाओं के उत्तरदायित्त्व में वृद्धि करना,
- शासन में जन-भागीदारी को बढ़ाना आदि
डेटा को सार्वजनिक संपत्ति क्यों माना जाना चाहिये?
- डेटा का सृजन लोगों के द्वारा लोगों के संबंध में और लोगों के लिये होना चाहिये।
- डेटा सार्वजनिक सेवाओं के समान ही कुछ विशेषताएँ रखता है-
- इसमें प्रतिस्पर्द्धा के गुण नहीं पाए जाते है अर्थात् यदि कोई एक व्यक्ति इसका उपयोग करता है तो यह उसी अनुपात में दूसरों के लिये समाप्त अथवा कम नहीं होता।
- डेटा को सुविधा के अनुसार विभिन्न लोगों की पहुँच से बाहर रखा जा सकता है, कुछ डेटाबेस फर्में शुल्क के माध्यम से ऐसा करती रहीं है।
- मज़बूत डेटा मैकेनिज्म सिस्टम केंद्र सरकार से लेकर स्थानीय सरकार के निकाय तक, नागरिकों से लेकर निजी क्षेत्र तक प्रत्येक हितधारक को सशक्त बना सकता है।
- यह कल्याणकारी योजनाओं में समावेश और बहिष्करण त्रुटियों को कम करके लक्ष्यीकरण त्रुटि को कम करने की क्षमता प्रदान करता है और बाज़ार को राष्ट्रीय स्तर पर एकीकृत करने, बिचौलियों की आवश्यकता को कम करने, अंतिम उपभोक्ताओं के लिए कीमतें कम करने और किसानों के लिए रिटर्न बढ़ाने की क्षमता प्रदान करता है।
- सभी खंडों में डेटा का समान रूप से दोहन नहीं किया जा रहा है। निजी कंपनियों के पास सामाजिक क्षेत्र से संबंधित डेटा के संग्रहण की कमी है क्योंकि वे सामाजिक कल्याण के लाभ से सरोकार नहीं रखते हैं, निजी कंपनियों द्वारा एकत्र किए जाने वाले डेटा की अधिकतम मात्रा और सामाजिक इष्टतम से कम हो जाती है।
- चूँकि निजी क्षेत्र द्वारा सामाजिक कल्याण के लिए डेटा इष्टतम मात्रा में उत्पन्न नहीं किया जा सकता है, सरकार को डेटा को सार्वजनिक रूप से देखने और इसमें आवश्यक निवेश करने की आवश्यकता है
- हालाँकि, कुछ प्रकार के डेटा हैं - विशेष रूप से सामाजिक हित के मुद्दों पर सरकारों द्वारा एकत्र किए गए डेटा - जिन्हें सामाजिक कल्याण हेतु लोकतांत्रिक बनाया जाना चाहिए।
सिस्टम का निर्माण
Building the Data System
- भारत सरकार लोगों के बारे में डेटा के चार अलग-अलग सेट रखती है-प्रशासनिक, सर्वेक्षण, संस्थागत और लेनदेन डेटा।
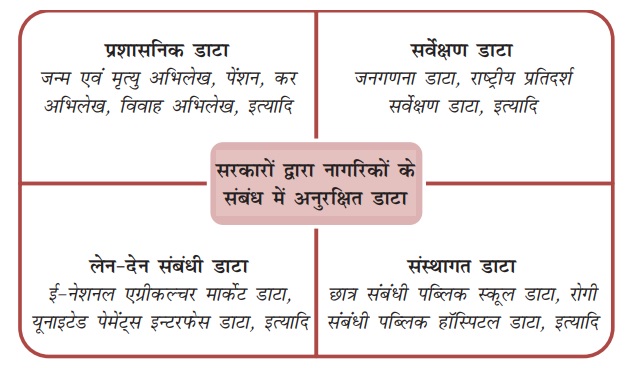
- सरकार प्रशासनिक आँकड़ों (डेटा) का रखरखाव मुख्यतः सांख्यिकीय प्रयोजनों के लिये करती है। प्रशासनिक डेटा समूहों के अंतर्गत जन्म-मृत्यु संबंधी अभिलेख, अपराध-रिपोर्ट, भूमि एवं संपत्ति पंजीकरण, वाहन पंजीकरण, राष्ट्रीय सीमाओं पर लोगों की आवाजाही, कर-अभिलेखों, आदि से जुड़े आँकड़ों को सम्मिलित किया जाता है।
- दूसरी ओर, सर्वेक्षण संबंधी आँकड़े, वे आँकड़े होते हैं जिन्हें व्यवस्थित, आवधिक सर्वेक्षणों के माध्यम से विशेष तौर पर सांख्यिकीय प्रयोजनों के लिये एकत्र किया जाता है। उदाहरण के लिये, राष्ट्रीय प्रतिदर्श सर्वेक्षण कार्यालय रोज़गार, शिक्षा, पोषण, साक्षरता, आदि पर देशभर में बड़े पैमाने पर प्रतिदर्श सर्वेक्षण करता है।
- संस्थागत आँकड़े लोगों के बारे में ऐसे आँकड़े होते हैं जो सार्वजनिक संस्थाओं द्वारा रखे जाते है। उदाहरण के लिये सरकार द्वारा संचालित जिला अस्पताल अपने मरीजों के चिकित्सा संबंधी समस्त अभिलेखों का रखरखाव करता है। सरकार द्वारा संचालित विद्यालय अपने छात्रों के संबंध में उनकी वैयक्तिक सूचनाओं का रखरखाव करता है।
- लेन-देन संबंधाी आँकड़े किसी व्यक्ति के लेनदेनों से संबंधित आँकड़े होते हैं, जैसे कि एकीकृत भुगतान इंटरफेस (यूपीआई) पर या भीम आधार पे पर किये जाने वाले भुगतान आँकड़ों की यह श्रेणी उदीयमान स्थिति में है, परंतु जैसे-जैसे लेन-देनों के कैशलैस भुगतान करने वाले लोगों की संख्या में वृद्धि होती जाएगी वैसे-वैसे ही इसका विकास होते जाने की संभावना है।
मौजूदा डेटा सिस्टम से जुड़े मुद्दे
- भारत में डेटा संग्रहण की व्यवस्था अत्यधिक विकेंद्रित स्थिति में है। सामाजिक कल्याण के प्रत्येक संकेतक के लिये आँकड़े एकत्र करने की ज़िम्मेदारी संबंधित संघीय मंत्रालय और इसके राज्य समकक्षों की होती है।
- फलतः एक मंत्रालय द्वारा एकत्र किये गए आँकड़ों को अन्य मंत्रालय द्वारा एकत्र किये गए आँकड़ों से पृथक रखा जाता है।
- उदाहरण के लिये किसी व्यक्ति के वाहन के रजिस्ट्रेशन संबंधी आँकड़ों को एक मंत्रालय द्वारा रखा जाता है, जबकि उसी व्यक्ति के सांपत्तिक स्वामित्व संबंधी अभिलेखों का रखरखाव किसी अन्य मंत्रालय द्वारा किया जाता है।
- ये डेटा-समूह राज्य द्वारा संचालित विश्वविद्यालय द्वारा उसी व्यक्ति की शैक्षिक उपलब्धियों संबंधी अभिलेखों से भी तथा दशवार्षिक जनगणना सर्वेक्षणों में एकत्र की गई अन्य जनांकिकीय सूचनाओं से भी परस्पर पृथक हो जाते हैं।
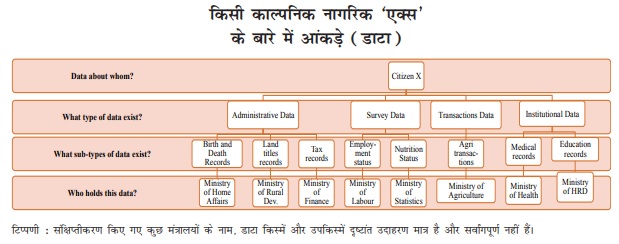
- इसलिए, अलग-अलग डेटासेट को एकीकृत करने की आवश्यकता है।
- एकीकृत प्रणाली की प्रभावकारिता तीन महत्त्वपूर्ण विशेषताओं पर निर्भर करती है।
- सबसे पहले मंत्रालयों को पूरा डेटाबेस देखने में सक्षम होना चाहिए, जबकि वे केवल उन डेटा क्षेत्रों में हेरफेर कर सकते हैं जो उनके अधिकार क्षेत्र में है।
- दूसरा, डेटा का अपडेशन वास्तविक समय में होना चाहिए और इस तरह से कि डेटाबेस के साथ एक मंत्रालय का जुड़ाव अन्य मंत्रालयों की पहुँच को प्रभावित न कर पाए।
- तीसरा और सबसे महत्त्वपूर्ण, डेटाबेस की सुरक्षा इतनी मज़बूत होनी चाहिये कि छेड़छाड़ की कोई भी संभावना न हो।
डेटा को एकीकृत करने की पहल
स्थानीय सरकारी निर्देशिका
Local Government Directory
- स्थानीय सरकारी निर्देशिका जो पंचायती राज मंत्रालय द्वारा विकसित किया गया एक कंप्यूटर-प्रोग्राम (एप्लिकेशन) है। इस स्थानीय सरकारी निर्देशिका में सभी स्थानीय एककों स्थानीय सरकारी निकायों के भू-क्षेत्र के प्लेटफार्म मानचित्र (जैसे कि ग्राम और उनकी संबंधित ग्राम पंचायतें) को सम्मिलित करते हुए वर्ष 2011 की जनगणना के अनुसार लोकेशन कोड निर्धारित किये गए हैं।
समग्र वेदिका पहल
Samagra Vedika Initiative
- तेलांगना सरकार की ‘समग्र वेदिका’ पहल से डेटा सेट एकीकरण कार्य के महत्वपूर्ण लाभ की महक आती है।
- इस पहल का संबंध सामान्य आइडेंटीफायर किसी व्यक्ति का नाम एवं पता का उपयोग करने वाले लगभग 25 मौजूदा सरकार के डेटा सेट से है।
- प्रत्येक व्यक्ति के बारे में सात श्रेणियों की सूचना को इस समूहन कार्य से जोड़ा गया था जो- अपराध, परिसंपत्तियां, उपयोगिताएं, सब्सिडी, शिक्षा, कर एवं पहचान थे।
- इसके अलावा प्रत्येक व्यक्ति को पति-पत्नी, भाई-बहन, माता-पिता और अन्य सगे संबंधियों से जोड़ा गया था।
सभी गोपनीयता चिंताओं को दूर करना
- प्रत्येक नागरिक से संबंधित ऐसी व्यापक, सर्वांगपूर्ण सूचना द्वारा सरकार को सशक्त करना प्रथम दृष्टि में भयभीत करने वाला हो सकता है। तथापि, यह सत्य से बहुत दूर है।
- पहला, अभी तक सरकारी रिकॉर्डों में विशाल मात्र में डेटा विद्यमान हो चुका है और इस योजना का प्रयोजन केवल इस उपलब्ध डेटा को अधिक प्रभावी विधि द्वारा उपयोग करना है।
- दूसरा, जहाँ लोग डेटा को प्रकट नहीं करना चाहते हैं तो वे ‘‘बाहर आने के विकल्प’’ का सदैव चयन करते हैं।
- तीसरा कुछ सार्वजनिक सेवाओं का कोई व्यवहार्य प्राइवेट बाज़ार का विकल्प न होने के बावजूद ऐसी सेवाओं से प्राप्त प्रत्येक व्यक्ति से संबद्ध डेटा को शेयर करने का विकल्प डेटा सुलभ न्यासी संरचना (Data Access Fiduciary Architecture) के अधीन सदैव नागरिक के पास ही उपलब्ध होगा।
‘डेटा एक्सेस फिड्यूशरी आर्किटेक्चर’
Data Access Fiduciary Architecture
- सरकार के प्रत्येक विभाग का यह दायित्व ह कि वह उसके पास उपलब्ध होने वाले डेटा को आगे उपलब्ध करवाए जोकि वह ‘डेटा प्रबंधक’ के रूप में धारण किये रखता है।
- इन विभागों को ‘निजी डेटा’ तथा ‘लोक डेटा’ द्वारा अपेक्षित मानकों के अनुसार संसाधित करते समय सावधानी रखनी होगी।
- ‘डेटा निवेदक’ को यह डेटा, ‘‘डेटा एक्सेस फिड्यूशरी’’ के माध्यम से उपलब्ध करवा दिया जाएगा। डेटा निवेदक सार्वजनिक अथवा निजी संस्थान दोनों में से कोई भी हो सकता है किंतु डेटा तक तभी पहुंच हो पाएगी जब उसके पास समुचित ‘प्रयोक्ता स्वीकृति’ होगी।
भारत के डेटा अवसंरचना का रूपांतरण्
- डेटा को प्रयोग में लाने के संबंध में चार कार्रवाई की जाती है यथा डेटा को एकत्रित करना, डेटा का भंडारण करना, डेटा का प्रक्रमण करना और डेटा का प्रसारण करना।
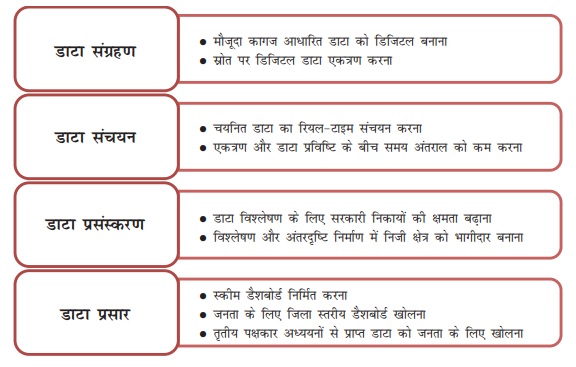
अनुप्रयोग
- एक सुदृढ़ डेटा बैकबोन समाज के प्रत्येक हितधारकों, केन्द्र सरकार से लेकर एक स्थानीय सरकारी निकाय को, नागरिकों से लेकर निजी संस्थानों को सशक्त कर सकता है।
- सरकार: सरकार समावेशी और बहिष्करण दोनों प्रकार की त्रुटियाँ कम करके कल्याणकारी योजनाओं और सब्सिडी के लक्ष्य में सुधार कर सकती है।
- निजी क्षेत्र: निजी क्षेत्र को व्यावसायिक उपयोग के लिये डेटाबेस चुनने का अधिकार दिया जा सकता है। सरकारी वित्त पर पड़ने वाले दबाव को कम करने के लिये उत्पन्न आँकड़ों के कम से कम एक हिस्से को मुद्रिकृत किया जाना चाहिये।
- नागरिक: नागरिक प्रस्तावित डेटा क्रांति के लाभार्थियों का सबसे बड़ा समूह है। उदाहरण के लिये: डिजिलॉकर क्लाउड में एक ही स्थान पर एक सत्यापित प्रारूप में इनके समस्त प्रलेखों को उपलब्ध कराता है।
- भारतीय रिजर्व बैंक ने नॉन-बैकिंग फाइनेंशियल कंपनी-अकाउंट एग्रीगेटर (एनबीएफसीएए) की घोषणा की है। एनबीएफसी-एए नागरिकों द्वारा अपेक्षित किसी भी प्रयोजन के लिये, प्रयोक्ताओं को एक साथ आँकड़े प्राप्त करने की सुविधा प्रदान करता है।
आगे की राह
सामाजिक कल्याण हेतु डेटा का सृजन इष्टतम परिमाण में निजी क्षेत्र द्वारा नहीं किया जा सकता अतः सरकार को लोगों की भलाई के साधन के रूप में डेटा को देखना चाहिये और आवश्यक निवेश कार्य करना चाहिये। लोक कल्याण के रूप में डेटा के सृजन के लाभों की प्राप्ति डेटा की निजता की कानूनी रूपरेखा के भीतर की जा सकती है। डेटा और सूचना हाइवे को भौतिक राजमार्गों की भांति समान रूप से महत्वपूर्ण अवसंरचना के रूप में देखा जाए। ऐसे कदम से भारत को अपने लोगों के कल्याण हेतु प्रौद्योगिकीय प्रगति के लाभों का गुणात्मक उपयोग करने में सहायता मिल सकती है।
महत्वपूर्ण तथ्य और रुझान
डेटा के एकत्रीकरण और संचयन में प्रौद्योगिकीय प्रगति को देखते हुए समाज का इष्टतम डेटा उपयोग पहले से अधिक हुआ है।
मेन्स के लिए महत्वपूर्ण प्रश्न
प्रश्न 1- डेटा का उपयोग इष्टतम सामाजिक कल्याण के लिए सीढ़ी के रूप में किया जा सकता है। डेटा को 'सार्वजनिक वस्तु' मानने के निहितार्थ का विश्लेषण कीजिये।
प्रश्न 2- उदाहरण की मदद से बताएं कि भारत के डेटा के बुनियादी ढांचे को कैसे बदला जा सकता है।



